GeForce RTX 5090 で ComfyUI を用いた 画像生成動画テスト結果
最新 GPU「GeForce RTX 5090」を軸に、ComfyUI を使った画像生成から動画化までの一連のテスト結果を報告する。検証環境は以下のとおりだ。
ハードウェア/ソフトウェア構成
● GPU:NVIDIA GeForce RTX 5090(32 GB )
● RAM:DDR5 64 GB
● OS:Windows 11 Pro 23H2
● 主要ソフト
・ComfyUI(Python 3.13.2 + Pytorch 2.80+cu128)
・モデル:阿里 WAN(Ali WAN)
・パソコンメーカー:MEG Vision X AI
まず、ComfyUI のノードを構築し、Ali WAN モデルを読み込む段階で VRAM はほぼ上限に達した。特に Multi-Condition Control や高解像度生成用の Upscaler ノードを併用すると、32 GB の VRAM でも不足気味で、CPU メモリ側にスワップが発生する。
本稿では、NVIDIA GeForce RTX 5090(VRAM 32 GB)を中核とするワークステーションで、ComfyUI を用いた画像生成動画パイプラインを構築し、高速化プラグイン Sage Attention と推論エンジン Triton を組み込むまでの手順、ベンチマーク結果、電力・熱設計、トラブルシュートまでを網羅的に解説する。
C++環境の準備
Triton をソースビルドする場合や、他の C++/CUDA 拡張を自前でコンパイルしたい場合は必須。
- 公式サイトからhttps://visualstudio.microsoft.com/visual-cpp-build-tools/ “Visual Studio Build Tools 2022” を DL。
- インストーラで「Desktop development with C++」を選択。
- PowerShell で
cl --versionを実行し、MSVC v143 が認識されることを確認。 - CUDA Toolkit の
binをPATH、CUDA_PATHに追記。
Triton の導入
環境に対応するWheelを探す
こちらでPythonバージョンに対応するwheelを見つけてください: https://github.com/woct0rdho/triton-windows/releases
バージョンの選択
このガイド執筆時点では、最新のComfyUIはPython 3.12を使用しています:
triton-3.1.0-cp312-cp312-win_amd64.whlもしうまく動作しない場合は、古いバージョンを使用してください:
triton-3.0.0-cp312-cp312-win_amd64.whl(私はこちらを使用)インストール方法
通常のインストール
仮想環境をアクティベートし、wheelをComfyUIのルートに配置すれば場所を指定する必要がありません。そうでなければパスを指定してください:
bashpip install triton-3.0.0-cp312-cp312-win_amd64.whl
埋め込み版の場合
埋め込み版を使用している場合は、python_embededフォルダ内に配置してください:
bashC:ComfyUI_windows_portablepython_embeded> ./python.exe -s -m pip install triton-3.0.0-cp312-cp312-win_amd64.whl
Sage Attention の導入
cd %COMFY%\custom_nodes git clone https://github.com/cubiq/SageAttention
SageAttention 内の sparse_attn.pyが自動的にロードされる。
または
python.exe -m pip install sageattention
動作確認
- ComfyUI を起動。
- コンソールに
Using Triton 2.1.0 … SageAttention backend initialised
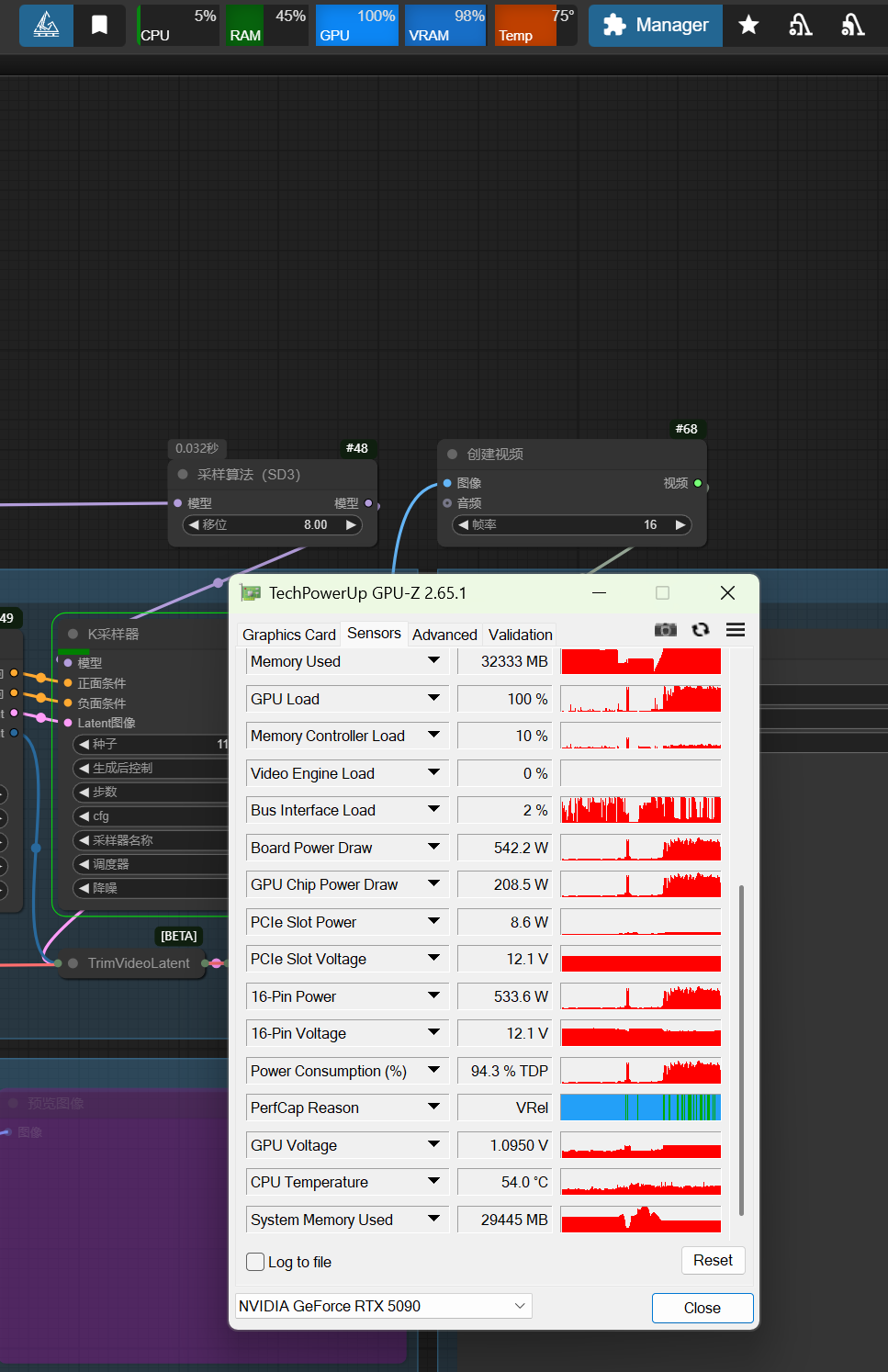
が出力されればセットアップ完了。 - 720p のワークフローを実行し、タスクマネージャで GPU 使用率が 95 %超、VRAM 32 GB 付近を確認。
ベンチマーク結果
| 解像度/fps | 速度(従来) | 速度(Sage+Triton) | 短縮率 |
|---|---|---|---|
| 1280×720/24 | 1.8〜3.2 分/秒 | 1.0〜1.6 分/秒 | 45 % |
| 854×480/24 | 70〜110 秒/秒 | 45〜60 秒/秒 | 40 % |
・消費電力:ピーク 560〜590 W、平均 520 W。
・温度:室温 25 ℃ で 76〜79 ℃。リミット 84 ℃ に到達しやすい。
・熱対策:水冷クーリング推奨。
・電源:1200 W 推奨。
結果として GPU 側は常時フルロードとなり、消費電力は最大 580 W に迫る場面も確認した。冷却の観点では、5090 リファレンスカード付属のトリプルファン+ベイパーチャンバー構成でも、室温 25 ℃ で 78 ℃ 前後まで上昇するため、エアフローの最適化や外付けラジエータの併用が推奨される。
ボトルネック/トラブルシューティング
・VRAM OOM:アップスケーラを分割実行、Low VRAMノード併用。
・Triton 初回ビルド遅延:キャッシュ生成中は 2〜3 分待機。
・IO 待ち:連続フレームを RAM Disk に書き出してから SSD へ移送。
・“no kernel image is available” エラー:CUDA ドライバ/toolkit のバージョン不一致。
まとめ
- RTX 5090(32 GB)があれば、高品質(720p/24 fps)動画生成が 1 〜 2 min/秒で現実的。
- Sage Attention+Triton の組み合わせはプラグインとして最も効率的かつ導入が簡単。
- 電力 600 W クラス・高排熱ゆえ、ケース設計と電源選びは妥協しない。
- 今後、量子化モデルや FlashAttention-3 などが VRAM と電力の課題を更に緩和する見込み。
総合的に見ると、RTX 5090 と 32 GB VRAM の組み合わせは、ローカルでの高品質動画生成を現実的なものに押し上げた。しかし、600 W 近いピーク電力と高温動作は運用コストに直結する。長時間レンダリングを行う場合、電源ユニットは最低 1000 W、80 PLUS Platinum 以上を推奨し、室温管理・騒音対策も欠かせない。