RTX5090でFlux Kontextモデルの3枚画像を1枚に融合して、素晴らしい!
RTX5090でFlux Kontextモデルの複数画像を1枚に融合するワークフローを試してみましたが、効果は素晴らしいです!

ワークフロー:
https://drive.google.com/file/d/1Fhdej5no_fn4xZmGuii9jTQvkc5dE2bp/view?usp=sharing
プロンプト技法
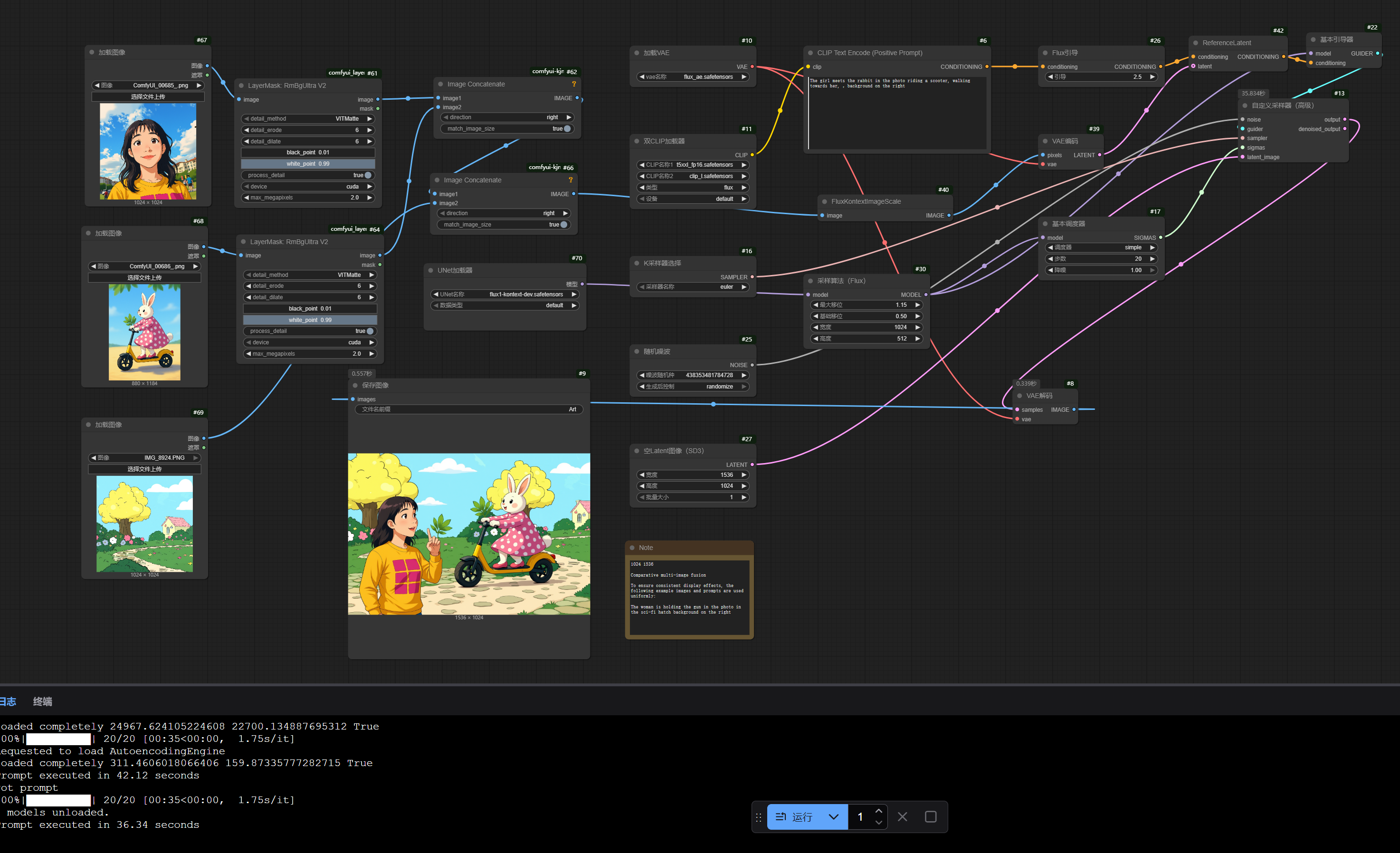
1枚目と2枚目の画像はキャラクターとアイテムにして、3枚目の画像は背景にするのがベストです。プロンプトには画像内の英語と「in the photo」を含めるのがよく、最後に「background on the right」を付けてください。
マルチ画像融合 一貫した表示効果を確保するため、以下の例では画像とプロンプトを統一して使用します:
The woman is holding the gun in the photo in the sci-fi hatch background on the right
The girl meets the rabbit in the photo riding a scooter, walking towards her, ,background on the right
エラー
以下のようなエラーが発生した場合:
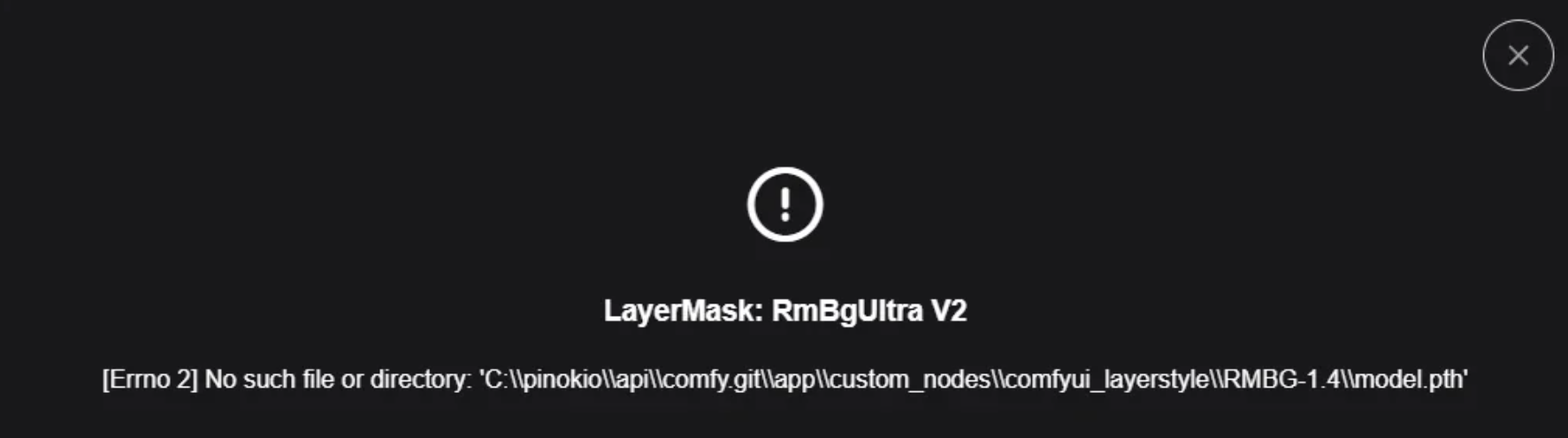
まずLayerstyleカスタムノードをインストールしてから、custom_nodesフォルダ内のLayerstyleノードディレクトリに直接入り、rmbg-1.4という名前のフォルダを作成してください。
そしてここから
https://huggingface.co/briaai/RMBG-1.4/tree/main
model.pthファイルをダウンロードし、作成したrmbg-1.4フォルダ内にそのファイルを保存してください。
必要なモデルファイルとセットアップ
ComfyUIでFLUX1-Kontextを使用するには、以下のファイルが必要です:
Diffusion Model
メインとなる拡散モデルは、Hugging Faceから2つの選択肢があります:
- オリジナル版:
flux1-kontext-dev.safetensors(約32GB VRAM必要) - https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev/blob/main/flux1-kontext-dev.safetensors
- FP8圧縮版:
flux1-dev-kontext_fp8_scaled.safetensors(約20GB VRAM必要) - https://huggingface.co/Comfy-Org/flux1-kontext-dev_ComfyUI/tree/main/split_files/diffusion_models
VAE(Variational Autoencoder)
ae.safetensors
text encoder
clip_l.safetensors:CLIP言語モデル- https://huggingface.co/comfyanonymous/flux_text_encoders/blob/main/clip_l.safetensors
t5xxl_fp16.safetensorsまたはt5xxl_fp8_e4m3fn_scaled.safetensors:T5テキストエンコーダー- https://huggingface.co/comfyanonymous/flux_text_encoders/blob/main/clip_l.safetensors
Model Storage Location
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── flux1-dev-kontext_fp8_scaled.safetensors
│ ├── 📂 vae/
│ │ └── ae.safetensor
│ └── 📂 text_encoders/
│ ├── clip_l.safetensors
│ └── t5xxl_fp16.safetensors 或者 t5xxl_fp8_e4m3fn_scaled.safetensors