RTX 5090でLTX-2 + Mel-Band RoFormerを使った口パク音楽動画生成テスト
今回は少し方向を変えて、動画生成(リップシンク)系の検証をしてみました。
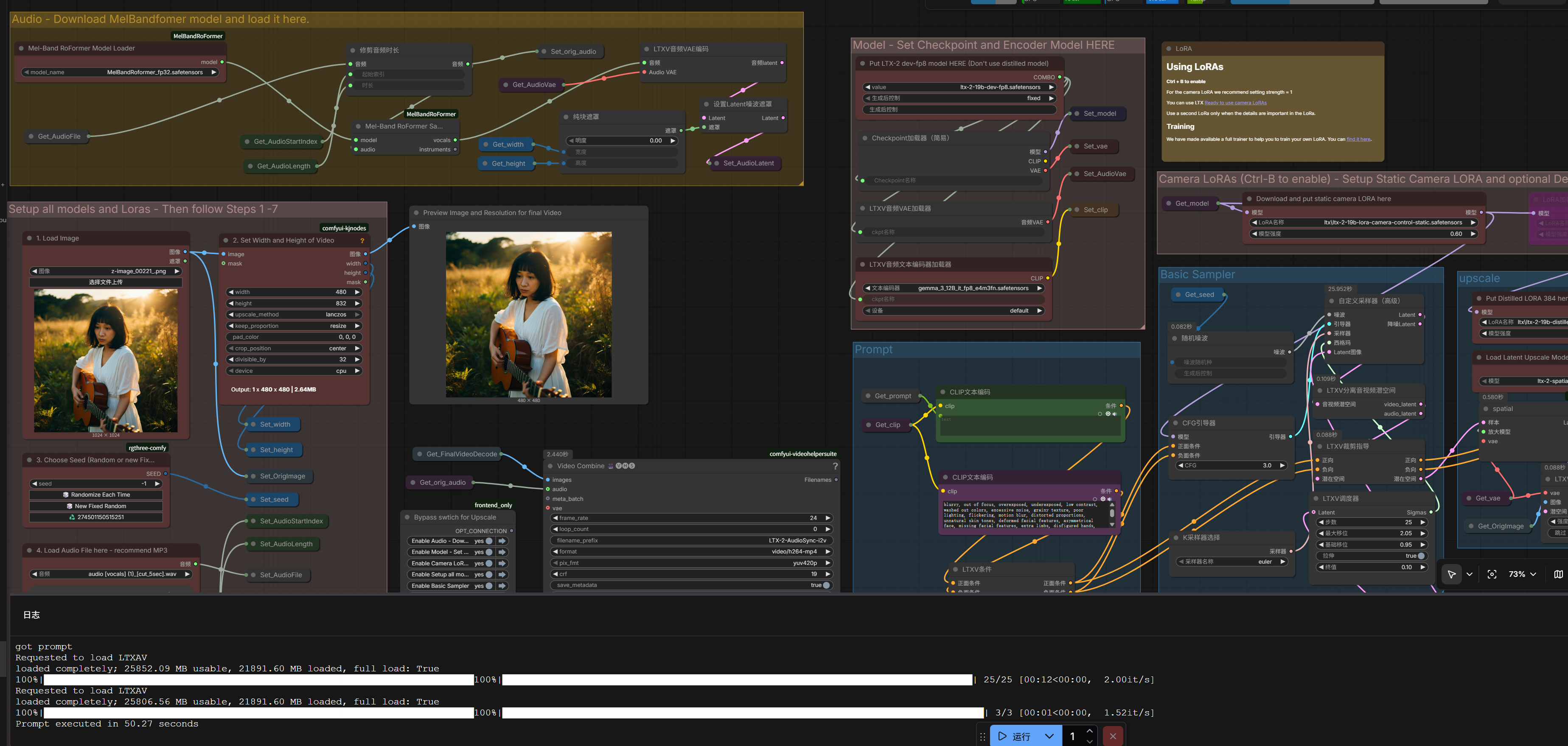
使用したのは以下の構成です:
- LTX-2(19B dev FP8)
- Mel-Band RoFormer(音声処理)
- ComfyUIワークフロー
結論から言うと、RTX5090で60秒の動画ごとに約25分程度かかる。
👉 「思ったより実用レベル。しかも速い」
というのが率直な感想です。
生成イメージ(イメージ例)
静止画1枚から、音声に合わせて自然に口が動く動画を生成できます。
リアル系でもアニメ系でも両方対応できるのはかなり便利です。
全体的な評価
今回の検証をまとめると:
- 生成速度:かなり速い(5090なら実用域)
- 精度:条件を整えれば良好
- 安定性:やや運要素あり(複数回生成推奨)
特に重要なのはここです。
👉 1回で完璧を狙わない方がいい
これは画像生成以上に顕著で、
複数回生成 → 良いものを選ぶという運用が前提になります。
重要なコツ(かなり大事)
今回試していて、一番効果があったのがこれです。
🎧 音声は「音楽」と「人声」を分離する
👉 これをやるだけでクオリティが一段上がる
理由としては:
- モデルが「口の動き=声」として認識しやすくなる
- 背景音(ドラム・伴奏)がノイズにならない
- タイミングのズレが減る
つまり、
👉 ボーカルだけを入力に使うのがベスト
音楽付きのままでも動きますが、
精度は明らかに落ちる印象でした。
もう一つの現実:長さ制限問題
このワークフローには明確な制約があります。
👉 1回で生成できる動画の長さが限られている
そのため、
- 音声を分割する必要がある
- それぞれ生成して後で結合
という手間が発生します。
正直ここはかなり面倒です。
特に、
- 曲の途中で切ると違和感が出やすい
- タイミング調整が地味に難しい
このあたりはまだ「実験段階感」があります。
使用モデル構成メモ(ローカル環境)
備忘録として、今回使った構成を整理しておきます。
■ Checkpoints
ltx-2-19b-dev-fp8.safetensorsMelBandRoformer_fp32.safetensors
■ Text Encoder
gemma_3_12B_it_fp8_e4m3fn.safetensors
■ LoRA
- LTX-2 Camera Control Static
- ltx-2 distilled lora(推奨強度:0.6)
■ Upscaler
- ltx-2 spatial upscaler x2
ディレクトリ構成
ComfyUI/
├── models/
│ ├── checkpoints/
│ ├── text_encoders/
│ ├── loras/
│ └── latent_upscale_models/
このあたりは標準的な構成なので、
普段ComfyUIを触っている人なら迷わないと思います。
ワークフローのポイント
基本的な流れは以下の通りです:
1. 画像を読み込む
ベースとなるキャラクター画像。
縦長(ポートレート)の場合は後述のLoRAが重要。
2. 解像度設定
リサイズノードで設定。
※32の倍数になるよう自動調整される点に注意。
3. Seed設定
- ランダム:バリエーション重視
- 固定:再現性重視
👉 基本はランダムで複数生成が良いです
4. 音声読み込み
MP3推奨。
(他形式も一応いけるが安定性はやや落ちる)
5. フレーム数設定
動画の長さをここで決定。
- 手動設定
- 音声長から自動計算(ノード接続)
👉 個人的には自動の方が楽でした
6. 開始位置指定
長い音声の場合:
👉 「何秒目から使うか」を指定可能
7. 音声長設定
ここ重要です。
👉 動画フレームより長い音声は途中で切れる
つまり、
- 音声長 ≤ フレーム長
を必ず守る必要があります。
Camera-Control LoRAについて
これはかなり重要です。
👉 Static Camera LoRAはほぼ必須
特に:
- 縦長画像
- ポートレート構図
の場合、これを使わないと
👉 ほぼ動かない(静止画のまま)
プロンプトに:
Static Camera
を入れて、強度1で使うのが安定でした。
LoRA強度について
distilled LoRAはデフォルト0.6に設定されていますが、
- リアル系:0.6が最適
- アニメ系:少し上げてもOK
という印象です。
👉 上げすぎると顔が崩れます
ここは割とシビアでした。
総評
今回の検証を一言でまとめると:
👉 「手間はかかるが、ちゃんと使えばかなり遊べる」
特に:
- VTuber風動画
- 歌唱シーン
- 簡易PV
このあたりには十分使えるレベルです。
良かった点
- 5090なら速度が実用域
- 画像1枚から動画生成できる手軽さ
- スタイル問わず動く(リアル・アニメ両対応)
気になった点
- 長尺動画が面倒(分割必須)
- 成功率が100%ではない
- 微妙な口ズレが出ることがある
おわりに(workflow)
正直、ここまで簡単に「喋る・歌う」が作れるとは思っていませんでした。
まだ荒削りではあるものの、
👉 「個人制作の表現力を一段引き上げるツール」
であることは間違いないです。
元画像はできるだけ顔を強調し、高解像度(例えば歯が見えるような表情)にしたほうが、動画の仕上がりが良くなると感じています。制作には時間がかかるため、今回の動画は一度だけ試して作ったものですが、それでもLTXはとても優秀だと思います。以前は、これほど短時間でこうした動画を作るのは難しかったです。
歌詞はGeminiの無料版で生成したものを使用しています。
画像は自分でAI-Toolkitを使ってz-imageのLoRAをトレーニングし、だいたい1~2回で満足できる結果が得られました。
この動画は4回に分けて制作し、1回あたり約25分かかりました。もし一度に作るとしたら約3時間は必要だと思いますし、仕上がりも不安だったため、完成後に編集ソフトで少し調整しました。もし作業を高速化する方法があれば、さらに良いと思います。
ltx2:https://drive.google.com/file/d/1zLDDv_F-e_J79ux9FDC9B7eUvEYBv5s7/view?usp=sharing
acestep1.5:https://drive.google.com/file/d/1nMiCWzJDrz6ZVQyV4AyMYI2FCLdJcqCU/view?usp=sharing
z-image lora:https://drive.google.com/file/d/1XRwu1AK5VplVSyu-PyJSz-wOJDgRgxsf/view?usp=sharing
今後は、
- 音声処理の最適化
- カット編集の効率化
- 長尺対応
このあたりが進めば、一気に実用度が上がりそうです。
もう少し触り込んだら、また続編を書こうと思います。