RTX 5090 で Musubi-Tuner をインストールし、Wan 2.2 の LoRA の作成方法
1. はじめに
Wan 2.2 は静止画でも動画でも他モデルを上回る仕上がりを見せます。これまで flux 系のモデルを多く作ってきましたが、人物の一貫性を保つため、今回は Wan 2.2 を試してみました。
環境は メモリ 64GB/GPU:RTX 5090(VRAM 32GB)。学習にかかった時間は以下の画像のとおりです。
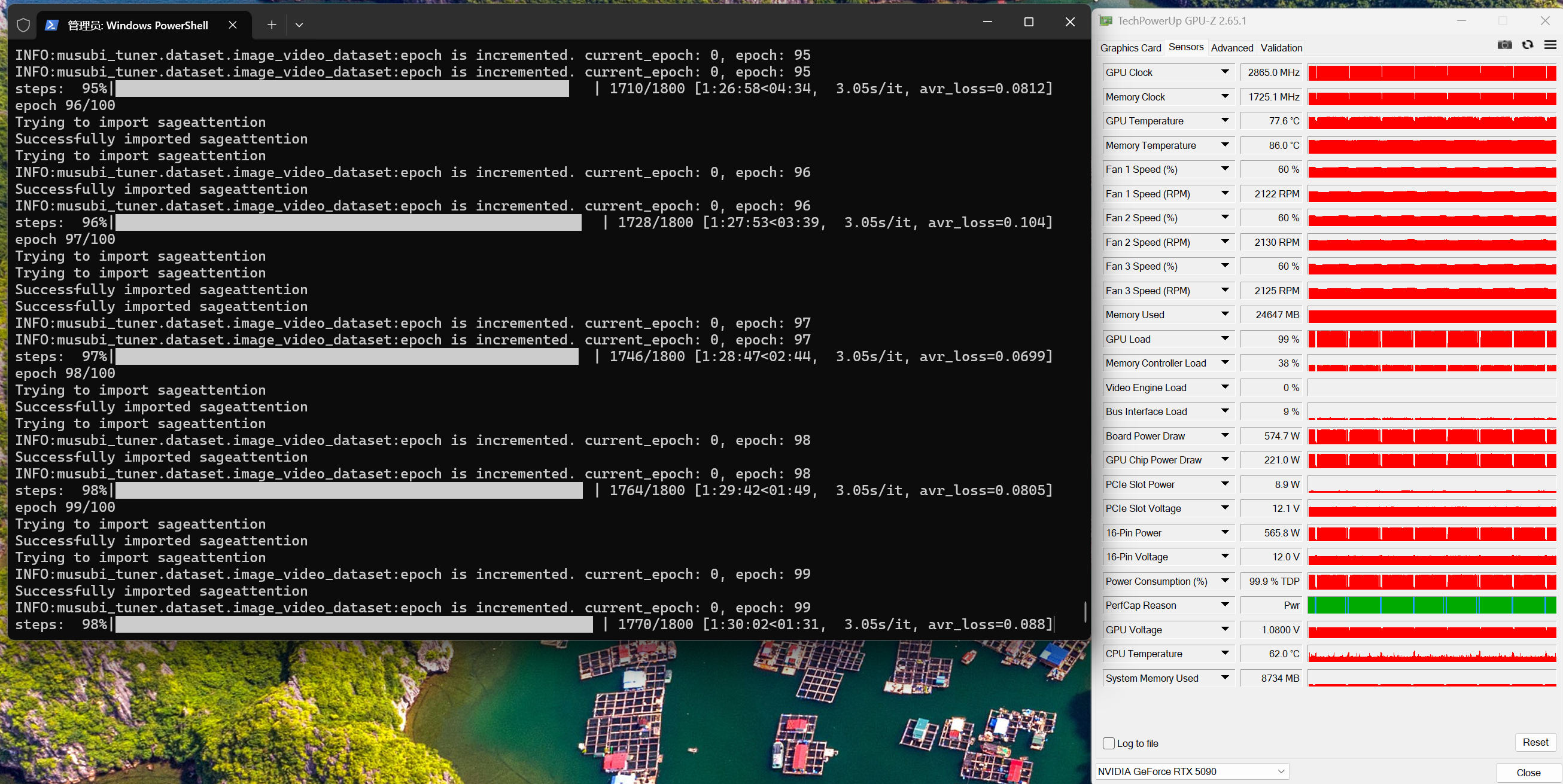
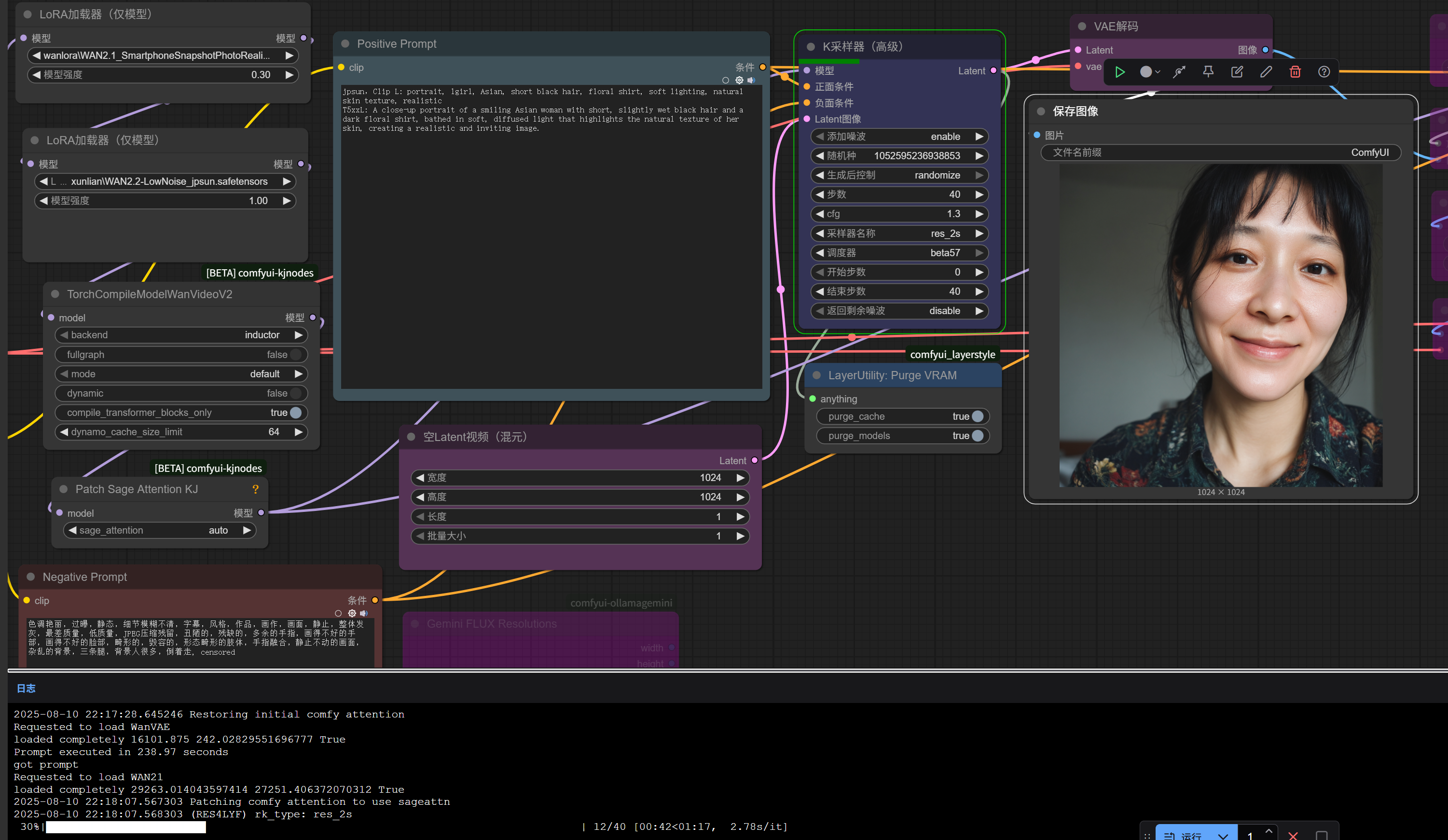
先に結論:高ノイズ/低ノイズの特性が異なるため、モデルは高ノイズ用と低ノイズ用をそれぞれ学習します(= 従来と違い 2 回学習)。 1 回あたり約 1 時間半、合計約 3 時間で 1 組の LoRA が得られます。低ノイズモデル単体でも画像生成は可能ですが、比較したところ高ノイズを加えると構図がより豊かになりました。
2. Musubi-Tuner のインストール
2.1 依存関係のインストール
# cmd を開き、ローカルにクローン
git clone https://github.com/kohya-ss/musubi-tuner.git
# ディレクトリへ移動
cd musubi-tuner
# Wan 2.2 対応のコミットへチェックアウト
git checkout d0a193061a23a51c90664282205d753605a641c1
# 仮想環境の作成と有効化
python -m venv venv
venv\Scripts\activate
python -m pip install --upgrade pip
# PyTorch など依存関係のインストール
pip install torch==2.7.0 torchvision==0.22.0 --index-url https://download.pytorch.org/whl/cu128
python -m pip install --upgrade pip wheel setuptools
pip install -U "triton-windows<3.4"
# ここから requirements_5090.txt をダウンロードして本フォルダに置き、実行
python -m pip install -r requirements_5090.txt
pip install xformers==0.0.30 --index-url https://download.pytorch.org/whl/cu128
pip install -e .
2.2 メモリ節約:Flash Attention(任意)
# こちらからダウンロード:
# https://github.com/sunsetcoder/flash-attention-windows/blob/main/flash_attn-2.7.0.post2-cp310-cp310-win_amd64.whl
# ダウンロードした .whl を Musubi-Tuner フォルダへ移動し、仮想環境を有効化した状態でインストール
pip install flash_attn-2.7.0.post2-cp310-cp310-win_amd64.whl
うまくいかない場合はビルドが必要です(30 分以上かかることがあります)。無理ならスキップ可。
pip install psutil
pip install flash-attn==2.7.0.post2 --find-links https://github.com/Dao-AILab/flash-attention/releases/expanded_assets/v2.7.0.post2
2.3 GPU 加速:Sage Attention(必須)
# こちらからダウンロード:
# https://github.com/sdbds/SageAttention-for-windows/releases/download/2.11_torch270%2Bcu128/sageattention-2.1.1+cu128torch2.7.0-cp310-cp310-win_amd64.whl
# ダウンロードした .whl を Musubi-Tuner フォルダへ移動し、仮想環境を有効化した状態でインストール
pip install sageattention-2.1.1+cu128torch2.7.0-cp310-cp310-win_amd64.whl
2.4 検証
python -c "import torch; print('PyTorch version:', torch.__version__); print('CUDA available:', torch.cuda.is_available())"
python -c "import xformers; import xformers.ops; print('xformers OK')"
python -c "import bitsandbytes as bnb; print(bnb.__version__); print(bnb.functional)"
上記の結果が問題なければ、ほぼ準備完了です。·

3. Wan 2.2 の学習用モデルをダウンロード
大容量ファイルを取得します。時間とディスクに余裕を用意してください。
Hugging Face CLI のインストール:
pip install huggingface_hub
モデルのダウンロード(順に実行):
- テキストエンコーダhuggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P models_t5_umt5-xxl-enc-bf16.pth –local-dir models/text_encoders
- VAEhuggingface-cli download Comfy-Org/Wan_2.1_ComfyUI_repackaged split_files/vae/wan_2.1_vae.safetensors –local-dir models/vae
- 拡散モデル(高ノイズ)huggingface-cli download Comfy-Org/Wan_2.2_ComfyUI_Repackaged split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp16.safetensors –local-dir models/diffusion_models
- 拡散モデル(低ノイズ)huggingface-cli download Comfy-Org/Wan_2.2_ComfyUI_Repackaged split_files/diffusion_models/wan2.2_t2v_low_noise_14B_fp16.safetensors –local-dir models/diffusion_models
注意点
- ファイルサイズ:数 GB〜数十 GB
- 所要時間:回線速度により数時間かかる場合あり
- ディスク容量:最低 100GB 以上推奨
- 認証:一部は Hugging Face のログインが必要な場合あり
4. Musubi-Tuner で Wan 2.2 の LoRA を学習
4.1 データ準備
画像でも動画でも可。ここでは人物の一貫性を重視した画像を例にします。
- 画像 18 枚+各画像に対応する .txt キャプション。 キャプション作成は GPT や Gemini の支援が便利です。
例(書式):
minimalist, hand-drawn, line art, black and white, 1girl, ponytail, apron, kitchen, diligent, A young woman with a ponytail diligently mopping a shiny kitchen floor, rendered in a minimalist, hand-drawn style with clean black and white lines, her apron slightly askew as she focuses on her task.
D:/lora/musubi-tuner/dataset/ に以下の dataset.toml を作成:
toml复制编辑# resolution, caption_extension, batch_size, num_repeats, enable_bucket, bucket_no_upscale は
# general または datasets のいずれかで設定(未設定はデフォルト値)
[general]
resolution = [1024 , 1024]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "D:/lora/musubi-tuner/dataset"
cache_directory = "D:/lora/musubi-tuner/dataset/cache"
num_repeats = 1 # 省略可。デフォルト 1。複数データセットのバランス調整に使用
# ここに他のデータセットも追加可。各データセットで個別設定が可能
4.2 事前キャッシュ生成
潜在キャッシュ(データセット/キャプションを変更するたびに再実行):
python src/musubi_tuner/wan_cache_latents.py --dataset_config "D:\lora\musubi-tuner\dataset\dataset.toml" --vae "D:\lora\musubi-tuner\models\vae\split_files\vae\wan_2.1_vae.safetensors"
テキストエンコーダ出力キャッシュ(同上、変更時は再実行):
python src/musubi_tuner/wan_cache_text_encoder_outputs.py --dataset_config "D:\lora\musubi-tuner\dataset\dataset.toml" --t5 "D:\lora\musubi-tuner\models\text_encoders\models_t5_umt5-xxl-enc-bf16.pth"
学習前に一度 accelerate の設定 を行ってください。
4.3 コマンド
高ノイズ用:
accelerate launch --num_cpu_threads_per_process 1 src/musubi_tuner/wan_train_network.py --task t2v-A14B --dit "D:\lora\musubi-tuner\models\diffusion_models\split_files\diffusion_models\wan2.2_t2v_high_noise_14B_fp16.safetensors" --vae "D:\lora\musubi-tuner\models\vae\split_files\vae\wan_2.1_vae.safetensors" --t5 "D:\lora\musubi-tuner\models\text_encoders\models_t5_umt5-xxl-enc-bf16.pth" --dataset_config "D:\lora\musubi-tuner\dataset\dataset.toml" --xformers --mixed_precision fp16 --fp8_base --optimizer_type adamw --learning_rate 3e-4 --gradient_checkpointing --gradient_accumulation_steps 1 --max_data_loader_n_workers 2 --network_module networks.lora_wan --network_dim 16 --network_alpha 16 --timestep_sampling shift --discrete_flow_shift 1.0 --max_train_epochs 100 --save_every_n_epochs 100 --seed 5 --optimizer_args weight_decay=0.1 --max_grad_norm 0 --lr_scheduler polynomial --lr_scheduler_power 8 --lr_scheduler_min_lr_ratio="5e-5" --output_dir "D:\lora\musubi-tuner\output" --output_name WAN2.2-HighNoise_linesun --metadata_title WAN2.2-HighNoise_linesun --metadata_author linesun --preserve_distribution_shape --min_timestep 875 --max_timestep 1000
低ノイズ用:
accelerate launch --num_cpu_threads_per_process 1 src/musubi_tuner/wan_train_network.py --task t2v-A14B --dit "D:\lora\musubi-tuner\models\diffusion_models\split_files\diffusion_models\wan2.2_t2v_low_noise_14B_fp16.safetensors" --vae "D:\lora\musubi-tuner\models\vae\split_files\vae\wan_2.1_vae.safetensors" --t5 "D:\lora\musubi-tuner\models\text_encoders\models_t5_umt5-xxl-enc-bf16.pth" --dataset_config "D:\lora\musubi-tuner\dataset\dataset.toml" --xformers --mixed_precision fp16 --fp8_base --optimizer_type adamw --learning_rate 3e-4 --gradient_checkpointing --gradient_accumulation_steps 1 --max_data_loader_n_workers 2 --network_module networks.lora_wan --network_dim 16 --network_alpha 16 --timestep_sampling shift --discrete_flow_shift 1.0 --max_train_epochs 100 --save_every_n_epochs 100 --seed 5 --optimizer_args weight_decay=0.1 --max_grad_norm 0 --lr_scheduler polynomial --lr_scheduler_power 8 --lr_scheduler_min_lr_ratio="5e-5" --output_dir "D:\lora\musubi-tuner\output" --output_name WAN2.2-LowNoise_linesun --metadata_title WAN2.2-LowNoise_linesun --metadata_author linesun --preserve_distribution_shape --min_timestep 0 --max_timestep 875
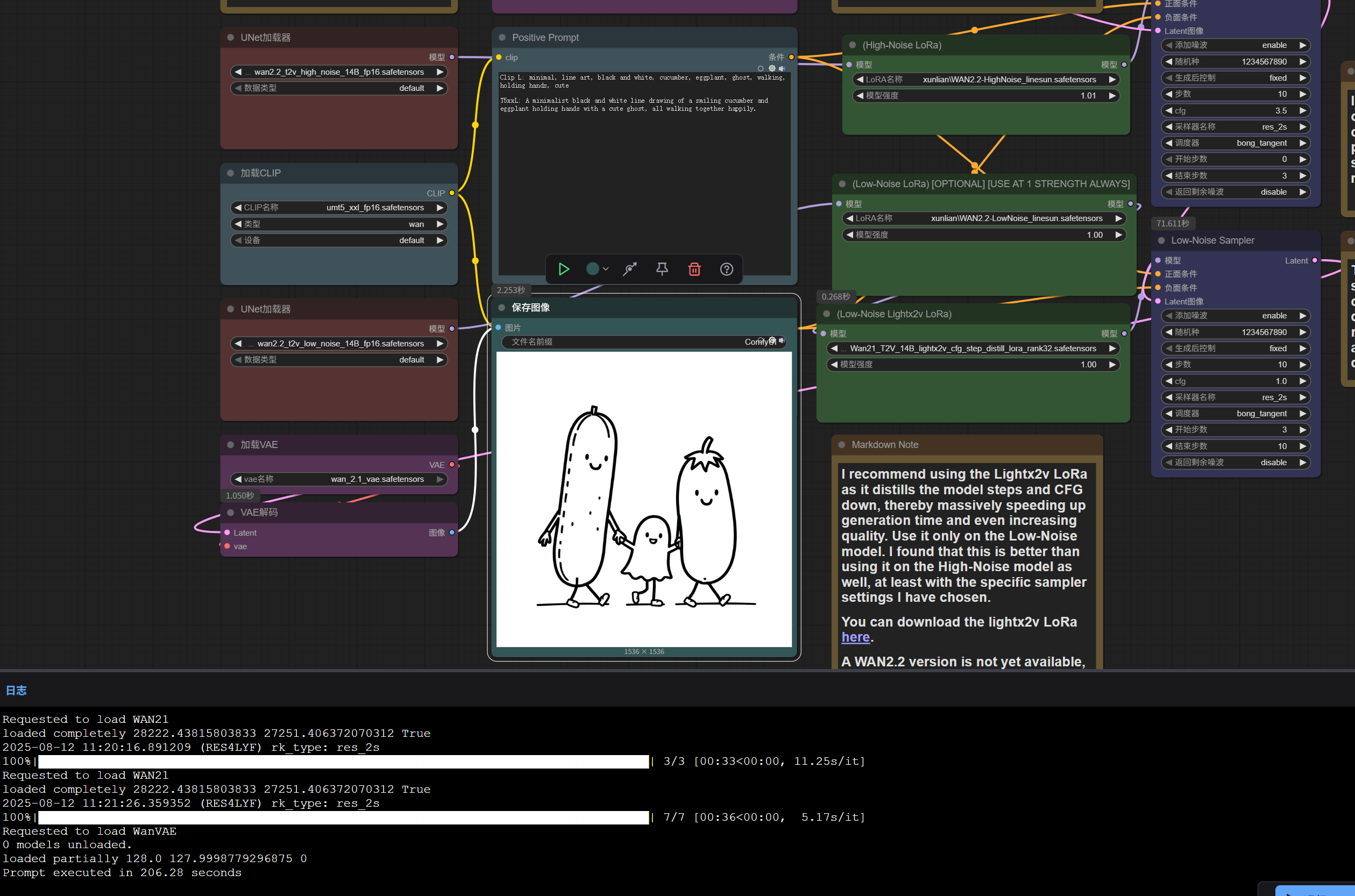
両者の違いは使用する拡散モデルとタイムステップ範囲のみで、他は同一です。 この設定で問題なく動作し、Wan 2.1 より明らかに良い結果が得られました。
なお、学習コマンドでは当初ガイドの dim=32 / alpha=4 から変更し、dim=16 / alpha=16、学習率スケジューラの power=8** にしています。これにより精度が良く、モデルサイズも約半分になります。
5. 再学習と運用
cd D:\lora\musubi-tuner
venv\Scripts\activate
作業ディレクトリへ移動し、仮想環境を有効化。前回のデータセットを削除して新しいデータセットに置き換えます。 /dataset/cache 内のファイルを削除し、コマンド中の --output_name(例の linesun 部分)を自分の LoRA 名に変更すれば OK です。