Kontext LoRAを再訓練しない場合、FLUX-devのLoRAを使ってキャラクターの一貫性を向上させる方法
Kontextは改めてLoRAを訓練し直す必要があるのでしょうか?KontextとFLUX-devのLoRAを組み合わせるとどのような結果が得られるのでしょうか?
Kontextとプロンプトを直接使用することでも、ある程度顔の一貫性を持った画像を生成できますが、確実性に欠けます。
ワークフロー
以下のワークフローを使用することで、
https://drive.google.com/file/d/1U8Ci13QfGpEv3upjpdZeC0V1Yk7lyCtQ/view?usp=sharing
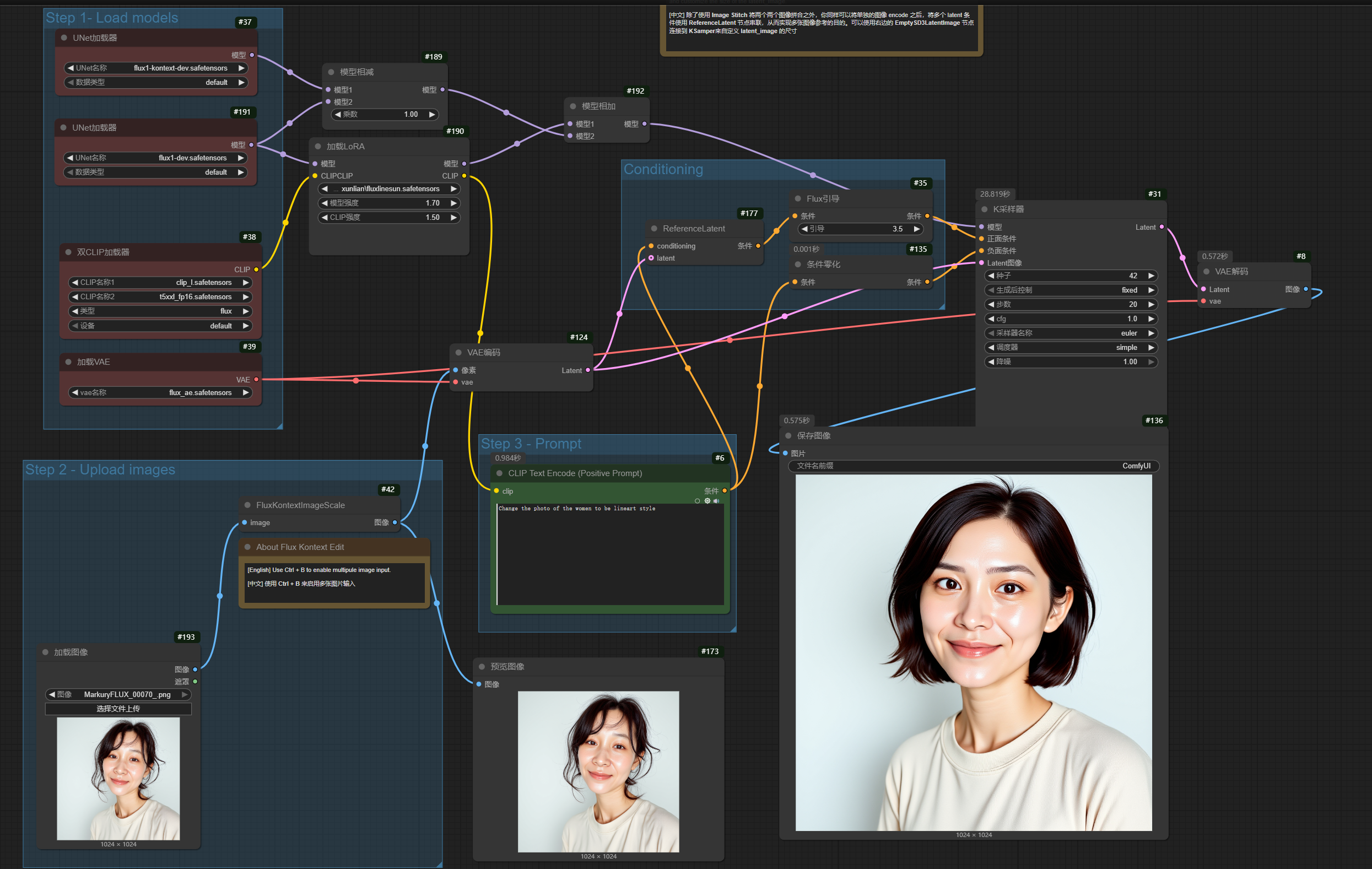
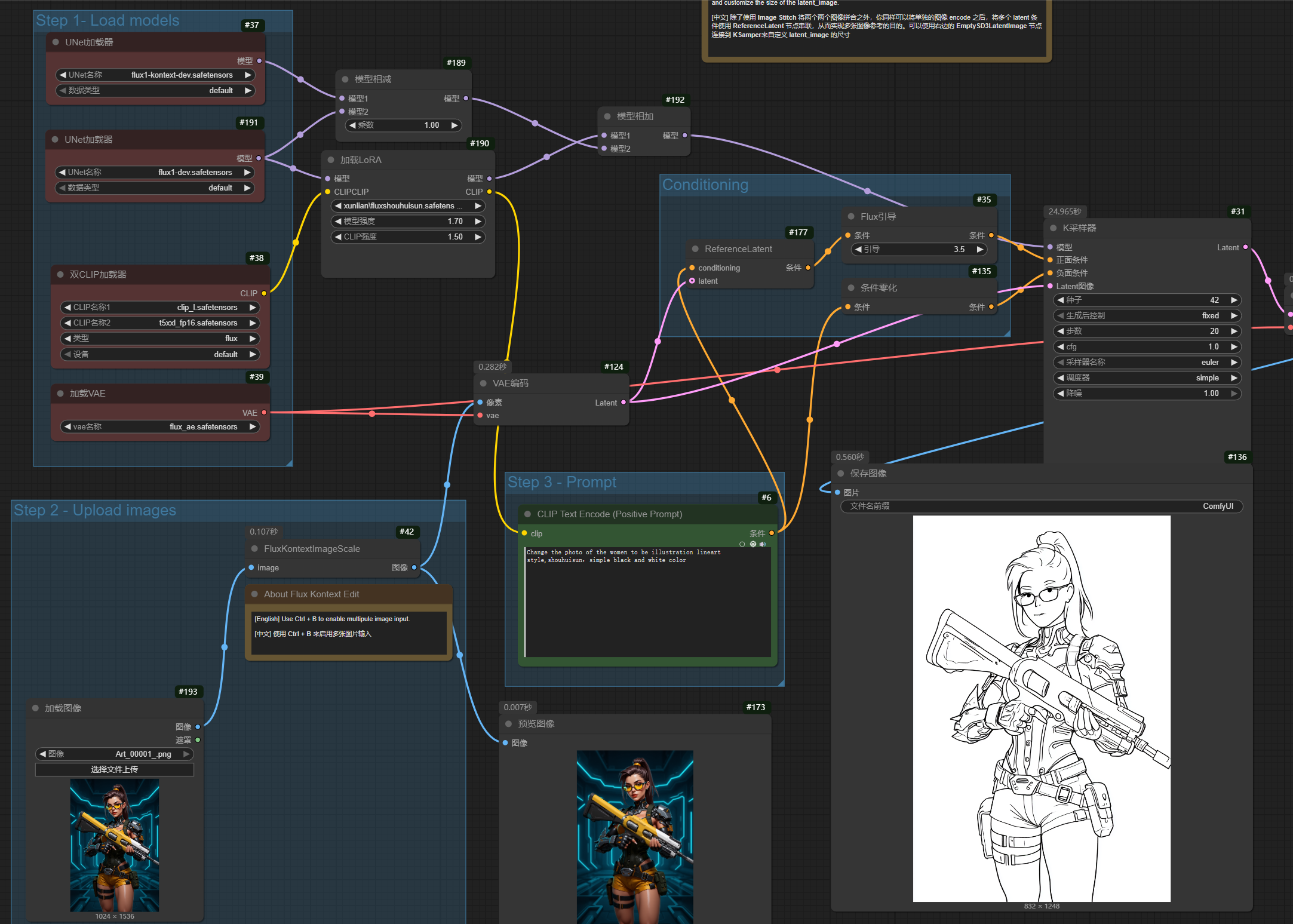
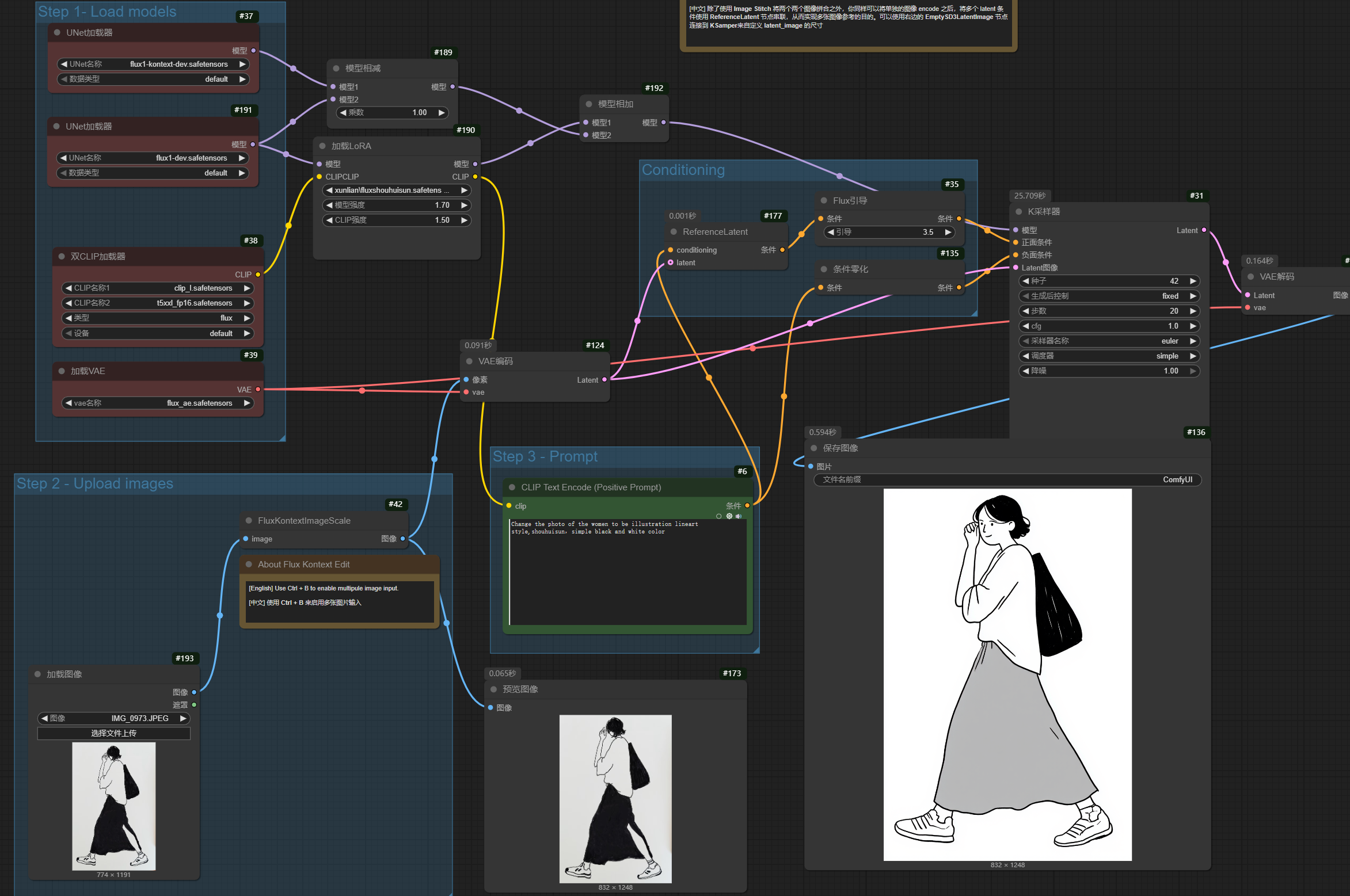
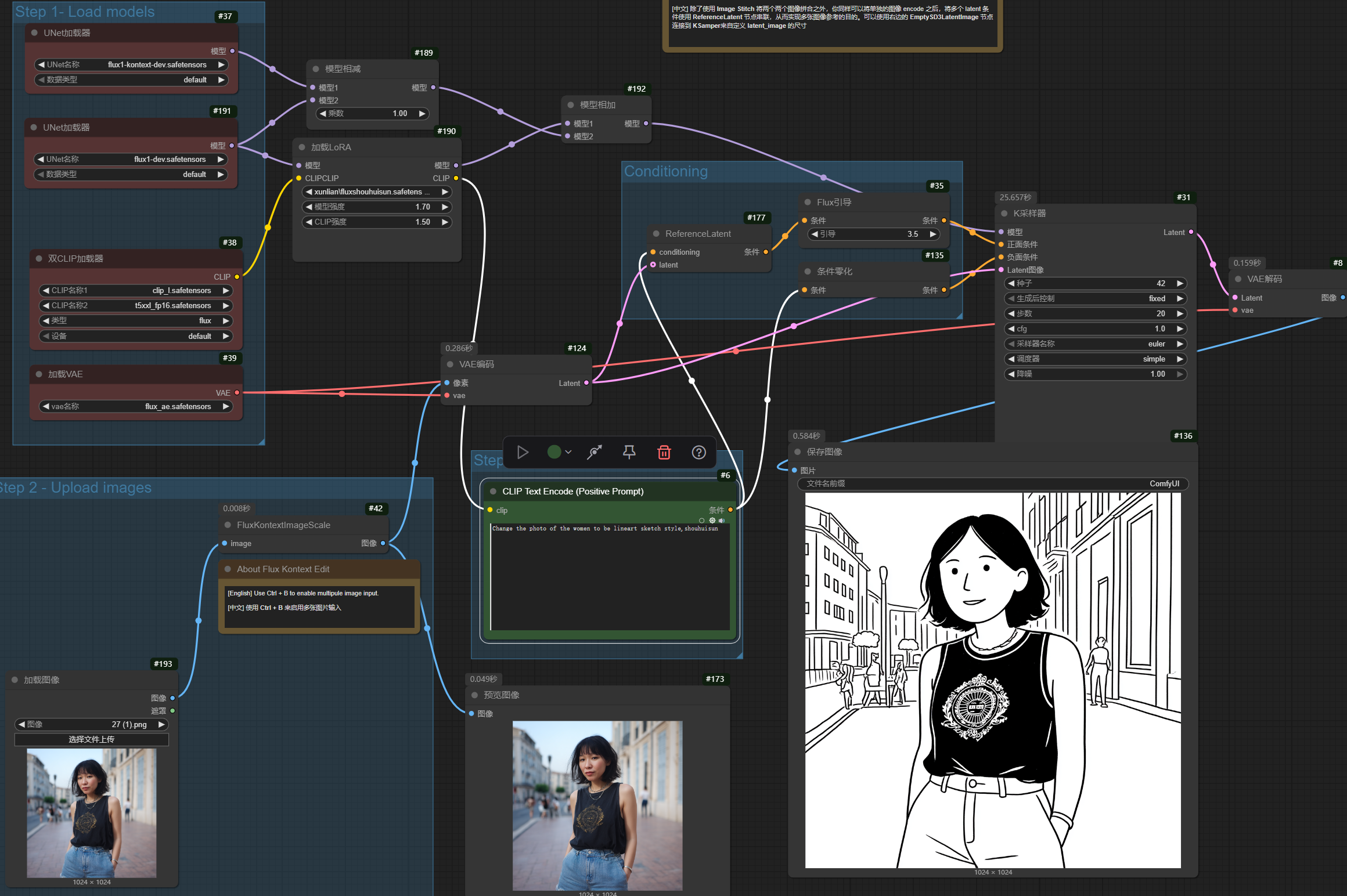
キャラクターLoRAがKontextと連携し、参考画像のポーズや表情、服装、動作を参照して画像を生成し、結果的に参考画像の顔を差し替える効果を得ることができることが分かりました。
核心原理:
- Kontextではなく、通常のFLUX-devを使用してLoRAを読み込む
- 並列ノードを作成し、Kontextの重みから統合されたDevの重みを減算する
- 生成された純粋なKontextの重みをLoRAの重みに統合する
- 1.5の強度でLoRAを使用する
テスト結果:
効果があるようです。ポーズや表情は読み込まれた画像を参考にし、顔部分はLoRAを使用しています。
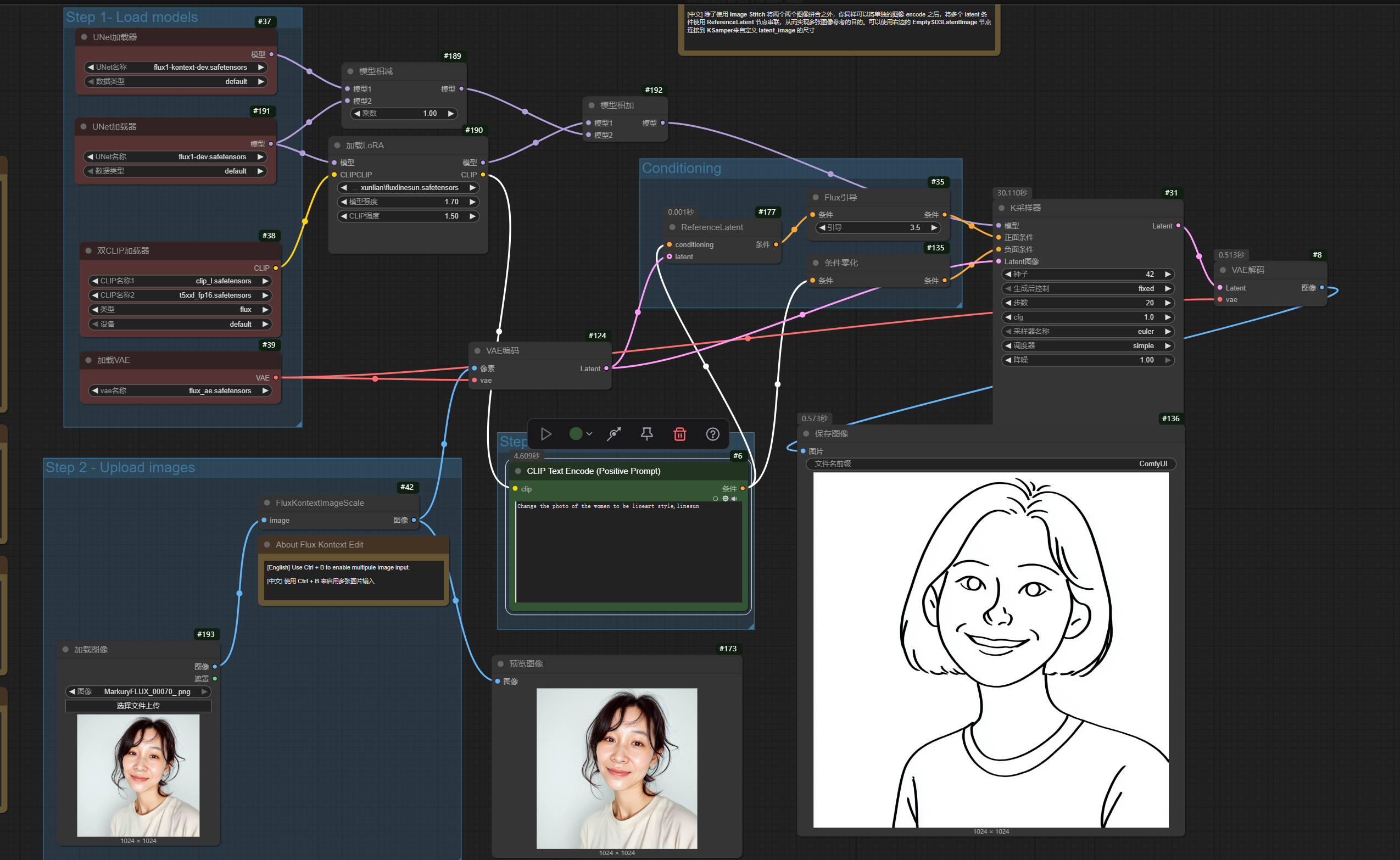
このプロンプトでLoRAトリガーワードを除去した後、スタイルも読み込まれた画像を参考にしました。LoRAトリガーワードを追加した後は、ポーズや表情は読み込まれた画像を参考にし、かつ顔部分はLoRAを使用しています。完璧です。