
#2 ママになったら不安だらけ!?
1.帰宅 娘が「ただいま」と帰宅。鼻をすすり、少し元気がない。母は心配そうに見つめる。 2検温 母は娘の額に手を当て、体温計を取り出す。娘は辛そうに目を閉じる。背景には学校の音楽会のチラシ。 3 困った 体温計をみた母は焦りの表情。音楽会のチラシを見つめ、複雑な心境。娘は咳をしている。 4 大丈夫 母は娘を優しく抱きしめる。「大丈夫」と安心させるように微笑む。
1.帰宅 娘が「ただいま」と帰宅。鼻をすすり、少し元気がない。母は心配そうに見つめる。 2検温 母は娘の額に手を当て、体温計を取り出す。娘は辛そうに目を閉じる。背景には学校の音楽会のチラシ。 3 困った 体温計をみた母は焦りの表情。音楽会のチラシを見つめ、複雑な心境。娘は咳をしている。 4 大丈夫 母は娘を優しく抱きしめる。「大丈夫」と安心させるように微笑む。
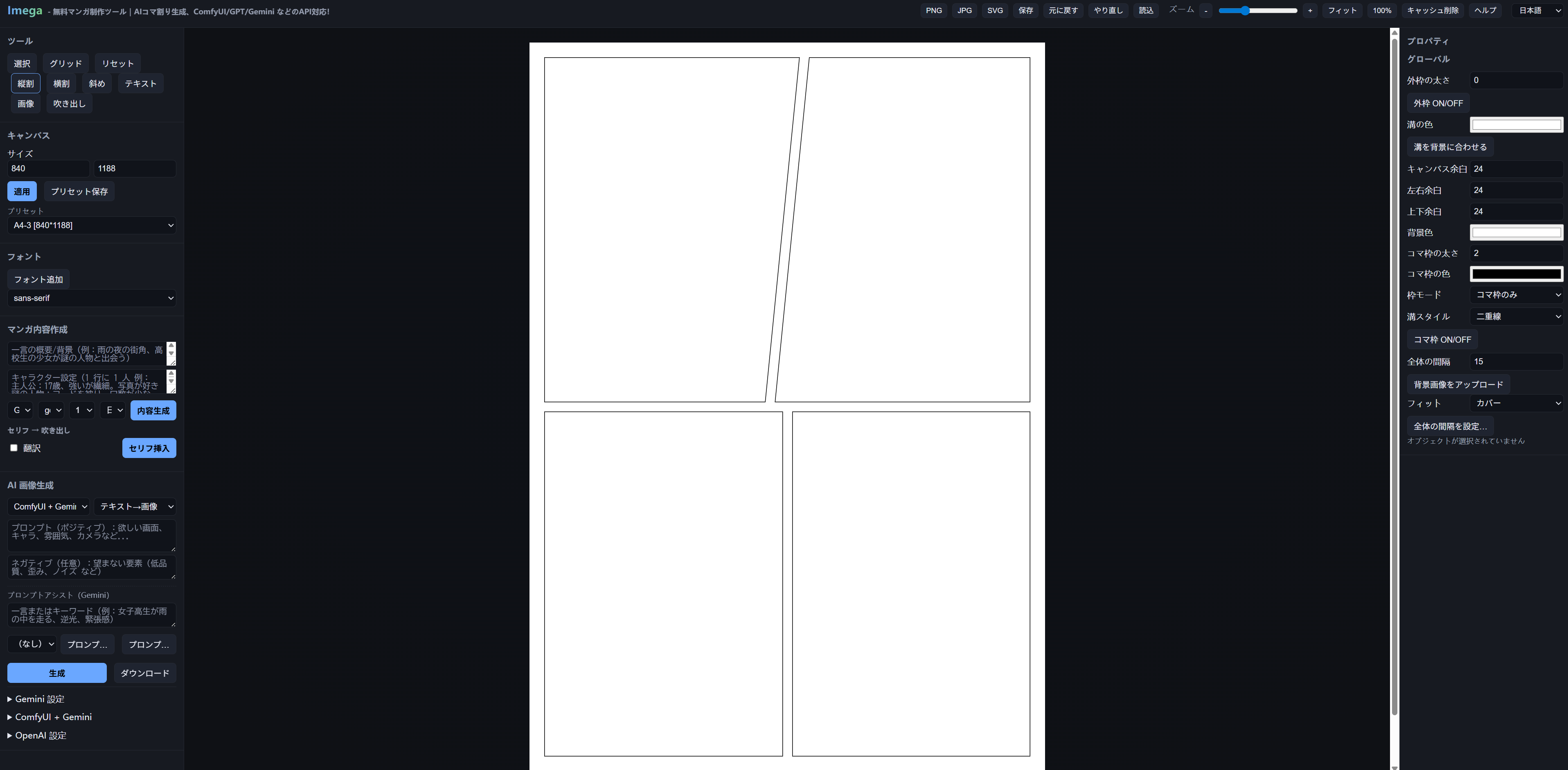
Web版漫画制作ツール紹介 もともと線画とか漫画が大好きで、当時はツールをめちゃくちゃ探してたんだけど、自分で描くのは苦手だし時間かかるし…。でも SD とか ComfyUI が出てきてからは、ほぼ3年ずっと使い続けてきたんだよね。その間いろんなモデルを試して、最近やっと Flux と WAN2.2 に出会って、「あ、これなら本気で自分の好きな漫画が作れる!」って思えるようになった。なんか、つまらない日でも「今日は無駄じゃなかったな」って思えるんだよ。 で、そこに GPT-5 の強力なコード力+自分のアイデアを組み合わせて、ついに小さい漫画編集ソフトを作った!別に新しいものでもレアでもなくて、自分の使いやすいように作っただけなんだけど、絵が苦手な自分にとってはかなり助かるツールになったと思う。 名前は 「imega」。意味は「イメージからマンガになろう」って感じで、口にしたらなんとなくこの単語になった(笑)。実際には存在しない言葉だけどね。で、imega のドメインは高すぎて買えなかったから、「場」をつけて いめがば** にした。ニュアンスとしては「イメージからマンガになろうの場所」って感じ。 アイデアが出てから公開まで、だいたい1か月くらいかかったかな。細かいところを何度も直して、コードもそんなに得意じゃないし。 サイト:https://imegaba.com/ ...

こういう体験って本当に面白いよね。普段は「まあ必要ないかな」って思ってるものほど、意外なタイミングでめちゃくちゃ役立ったりするんだよ。今回もまさにそれで、靴カバーなんて入れてたことすら忘れてたのに、雨の日に大活躍してくれてさ。あの瞬間、「自分ナイス!」ってちょっと誇らしくなった(笑)。 やっぱり「準備しておくこと」って大事なんだなって改めて感じたよ。しかも、準備してても使わないことの方が多いけど、たった一度でも役に立てば、それだけで全部報われる気がするんだよね。今回みたいに。だからこれからも「もしかしたら必要かも?」って思ったら、とりあえず持っていこうって思った。備えあれば憂いなし、ってやつだね。
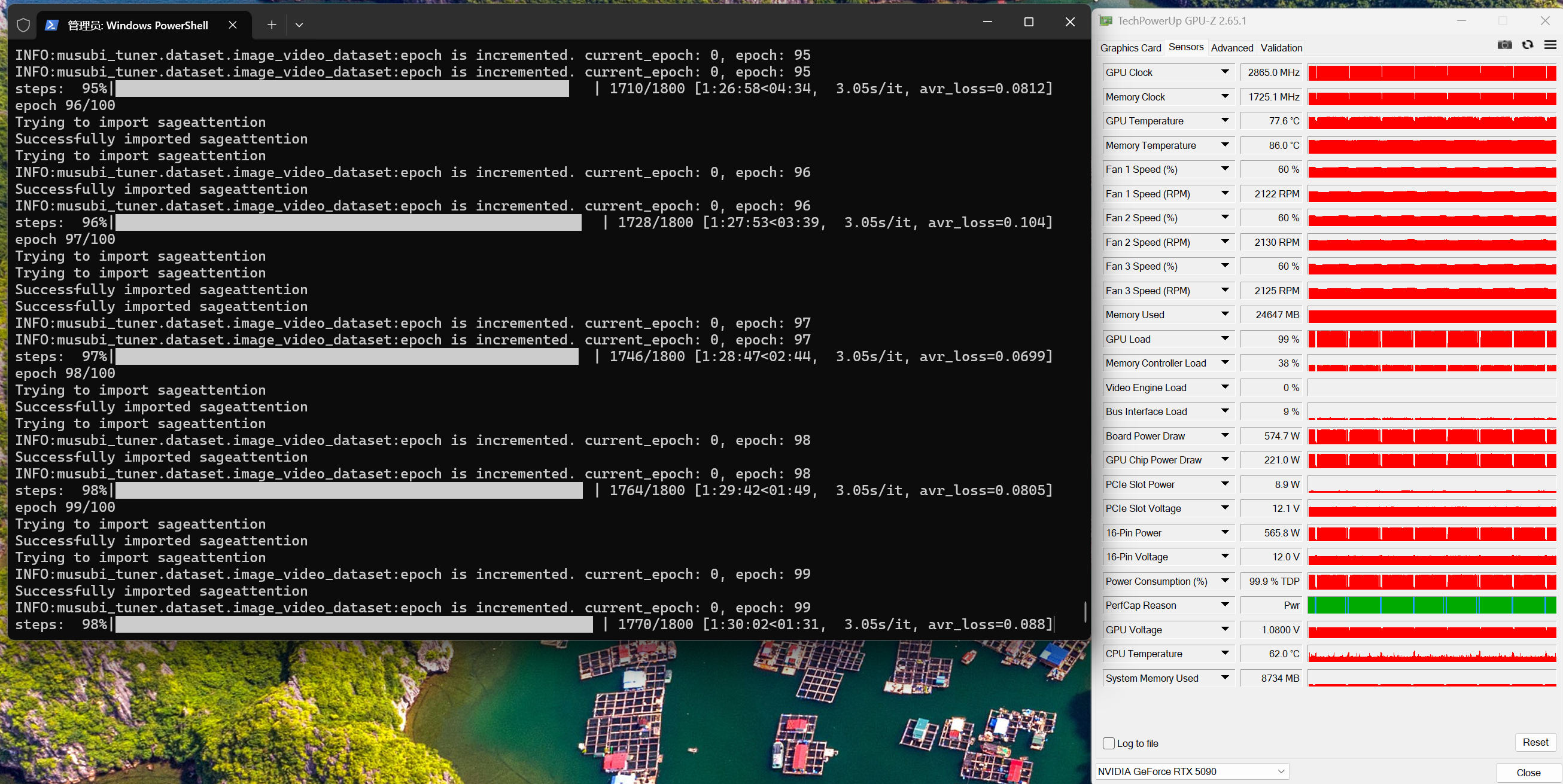
1. はじめに Wan 2.2 は静止画でも動画でも他モデルを上回る仕上がりを見せます。これまで flux 系のモデルを多く作ってきましたが、人物の一貫性を保つため、今回は Wan 2.2 を試してみました。 環境は メモリ 64GB/GPU:RTX 5090(VRAM 32GB)。学習にかかった時間は以下の画像のとおりです。 先に結論:高ノイズ/低ノイズの特性が異なるため、モデルは高ノイズ用と低ノイズ用をそれぞれ学習します(= 従来と違い 2 回学習)。 1...

ウサギとカメ manga, comic, monochrome,Panel One: Scene: A rabbit is singing a cheerful song, musical notes floating above its head. A...

WAN2.2のT2V(Text-to-Video)モデルを使って画像生成を試してみたところ、驚くべき結果が得られました。なんと、Fluxモデルで問題となっていた肌のプラスチック感を完全に解消できたのです! RTX5090での検証結果、効果は特に素晴らしいものでした! 使用モデル wan2.2_t2v_low_noise_14B_fp16.safetensors 使用ノード構成 生成速度 処理時間の内訳は以下の通りです: 処理段階設定所要時間基本生成40ステップ約60秒アップスケール2048×204890秒合計処理時間-150秒 Fluxとの比較優位性 従来のFluxモデルでは、特に人物の肌質表現において「プラスチックのような不自然な質感」が課題となっていました。しかし、WAN2.2のT2Vモデルを使用することで: これらの改善により、画像生成の品質が大幅に向上しました。 ワークフローのダウンロード https://drive.google.com/file/d/102b0Lw9JJ80J8xVnNY08e5d2OMhvPYwX/view?usp=sharing まとめ WAN2.2のT2Vモデルは、従来のFluxモデルの弱点を克服した画期的なモデルです。RTX5090との組み合わせにより、高品質な画像を短時間で生成できる実用的なソリューションとなっています。 特に人物画像の生成において、自然な肌質表現を求めるクリエイターにとって、このモデルは非常に価値のあるツールになるでしょう。 総処理時間150秒で高品質な2048×2048の画像が生成できる効率性も、実用面での大きなメリットです。

RTX5090を使ってWAN2.2の最新画像生成動画モデルを試用してみました。以前のバージョンと比べて安定性が大幅に向上していることを実感できました。 1. ComfyUIのアップグレード まず、ComfyUIを最新版にアップグレードする必要があります。 仮想環境の有効化 bash conda activate comfyui ディレクトリに移動してアップデート bash cd <ComfyUI-installation-path>git pullpip install -r requirements.txtpython main.py 2. ワークフローのダウンロード...
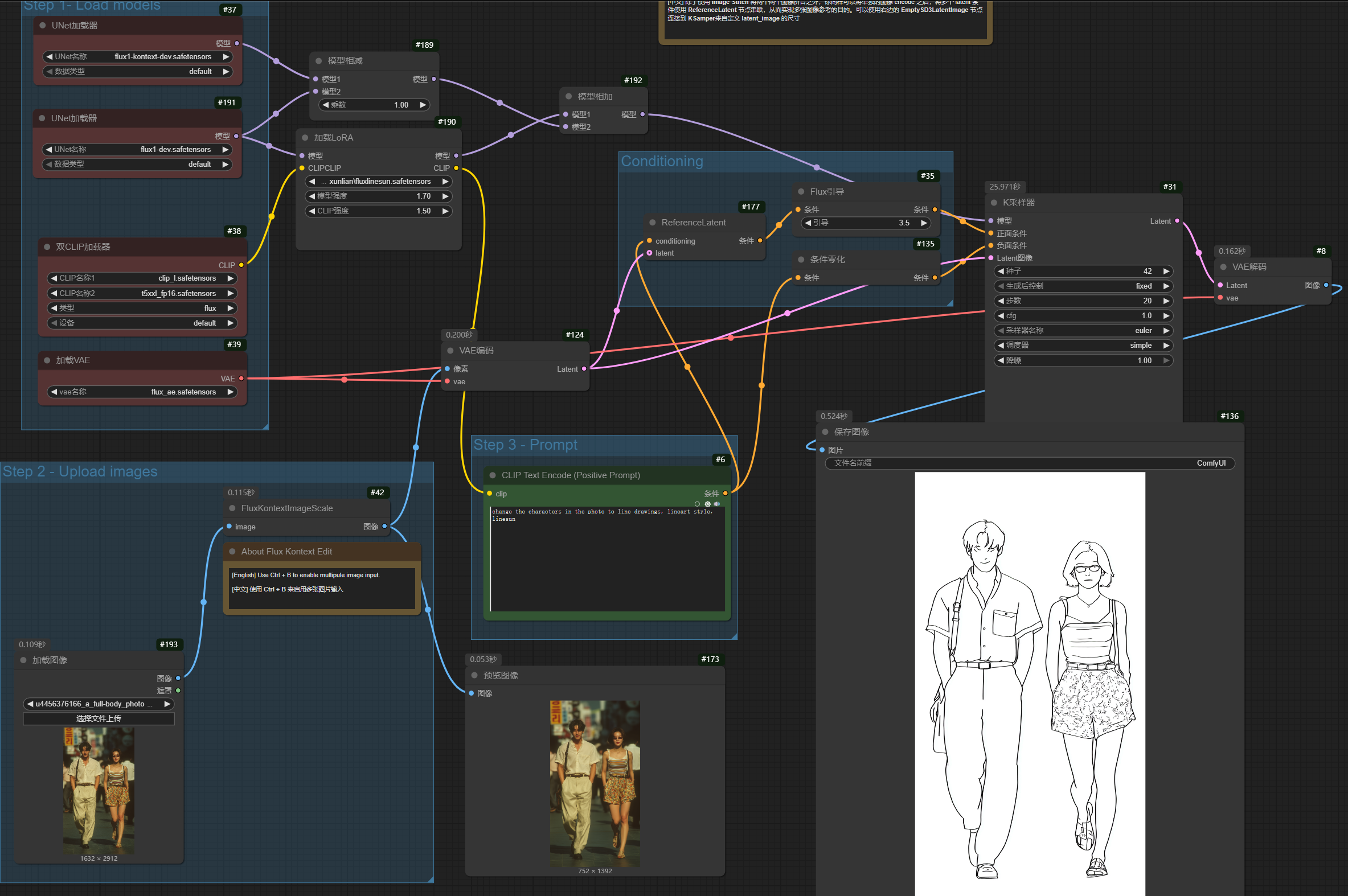
私は以前からminimalist、線画風のアート作品にとても魅力を感じていました。そのシンプルでありながら表現力豊かな線の美しさに惹かれ、自分でもそのような作品を作ってみたいと思っていました。 LoRAについて https://drive.google.com/file/d/1JeFMQ8JGv0WjOD0V_GynFR1h3VX0YSDL/view?usp=sharing ここから fluxlinesun をダウンロードして!トリガーワード:linesun prompt:change the characters in the photo to line drawings,lineart style,linesun change the subjects in the...
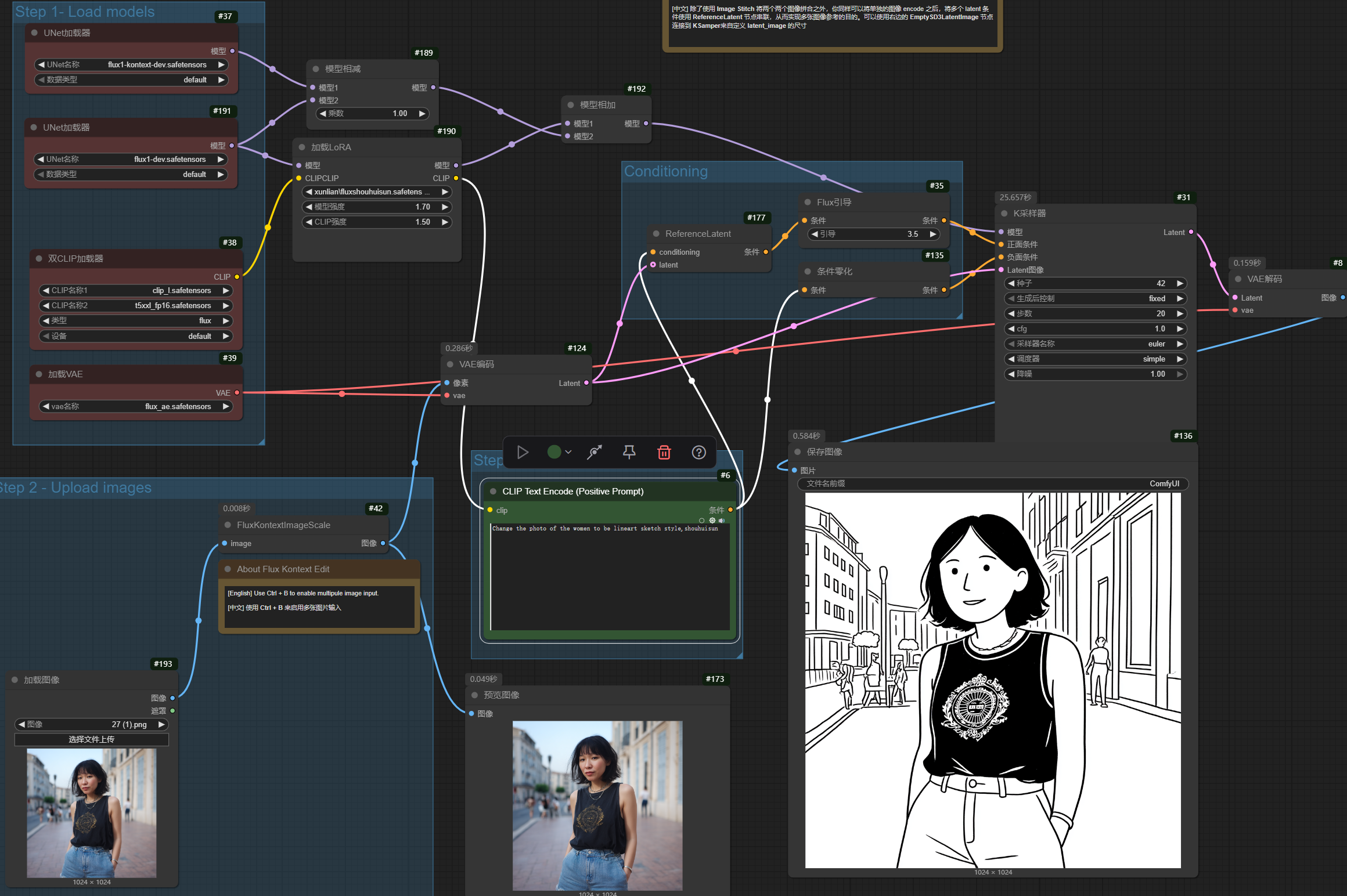
Kontextは改めてLoRAを訓練し直す必要があるのでしょうか?KontextとFLUX-devのLoRAを組み合わせるとどのような結果が得られるのでしょうか? Kontextとプロンプトを直接使用することでも、ある程度顔の一貫性を持った画像を生成できますが、確実性に欠けます。 ワークフロー 以下のワークフローを使用することで、 https://drive.google.com/file/d/1U8Ci13QfGpEv3upjpdZeC0V1Yk7lyCtQ/view?usp=sharing キャラクターLoRAがKontextと連携し、参考画像のポーズや表情、服装、動作を参照して画像を生成し、結果的に参考画像の顔を差し替える効果を得ることができることが分かりました。 核心原理: テスト結果: 効果があるようです。ポーズや表情は読み込まれた画像を参考にし、顔部分はLoRAを使用しています。 このプロンプトでLoRAトリガーワードを除去した後、スタイルも読み込まれた画像を参考にしました。LoRAトリガーワードを追加した後は、ポーズや表情は読み込まれた画像を参考にし、かつ顔部分はLoRAを使用しています。完璧です。

RTX5090でFlux Kontextモデルの複数画像を1枚に融合するワークフローを試してみましたが、効果は素晴らしいです! ワークフロー: https://drive.google.com/file/d/1Fhdej5no_fn4xZmGuii9jTQvkc5dE2bp/view?usp=sharing プロンプト技法 1枚目と2枚目の画像はキャラクターとアイテムにして、3枚目の画像は背景にするのがベストです。プロンプトには画像内の英語と「in the photo」を含めるのがよく、最後に「background on the right」を付けてください。 マルチ画像融合 一貫した表示効果を確保するため、以下の例では画像とプロンプトを統一して使用します: The woman is holding the gun in...

Black Forest Labsが開発したAI画像生成技術の新たな可能性を示す革新的なモデルFLUX1-Kontextが、ついにComfyUIでの利用が可能になりました。今回は、最新のRTX 5090を使用して実際の性能を検証し、効果的なプロンプト技法についても詳しく解説します。 FLUX1-Kontextとは FLUX1-Kontextは、従来のFLUXモデルの進化版として位置づけられる画像生成モデルです。特に画像の編集や変換において優れた性能を発揮し、既存の画像に対して精密な修正や風格変換を行うことができます。このモデルの最大の特徴は、原画像の構図や重要な要素を保持しながら、指定された部分のみを自然に変更できる点にあります。 必要なモデルファイル ComfyUIでFLUX1-Kontextを使用するには、以下のファイルが必要です: Diffusion Model メインとなる拡散モデルは、Hugging Faceから2つの選択肢があります: VAE(Variational Autoencoder) ae.safetensors https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/blob/main/split_files/vae/ae.safetensors text encoder Model Storage...
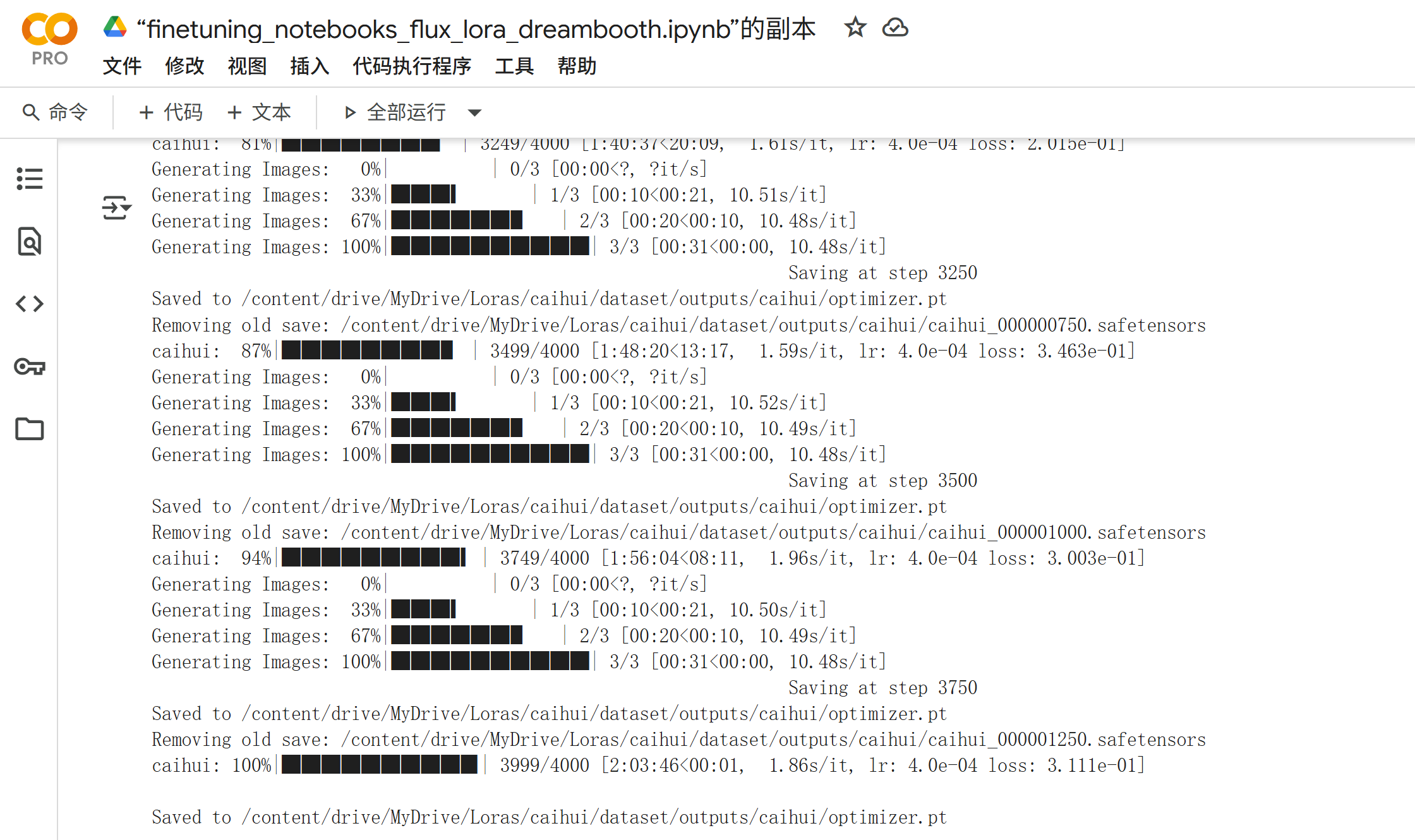
はじめに Comfyuiで、LoRAモデルの重要性はますます高まっています。特にFluxモデルでのLoRAトレーニングは、個性的なキャラクターや独特なアーティスティックスタイルを再現するために欠かせない技術となっています。 私は自宅にRTX 5090を所有していますが、LoRAモデルのトレーニングにおいてGoogle Colabを選択している理由があります。RTX 5090は間違いなく強力なGPUですが、消費電力が非常に高く、長時間のトレーニングセッションでは電気代が気になります。さらに、数時間連続で動作させると発熱も相当なものになり、負荷が心配になります。 そこで、Google ColabのA100 GPUを活用することで、これらの問題を解決しながら効率的にLoRAモデルをトレーニングする方法をご紹介します。 Ⅰ:写真選択 数量15ー50 キャラクターLoRAの場合 キャラクターLoRAを作成する際の写真選択は、最終的な品質を決定する最も重要な要素の一つです。以下の基準を厳密に守ることで、原人物に非常に近いLoRAモデルを作成できます。 背景除去の重要性 まず、すべての写真から背景を完全に除去し、人物のみを残すことが重要です。背景が残っていると、モデルが人物の特徴ではなく背景の要素を学習してしまう可能性があります。この作業は手間がかかりますが、最終的な品質に大きく影響するため妥協できません。 comfyuiで背景を除去方法: https://shiokoto.com/archives/72 解像度とサイズの最適化 写真の解像度は可能な限り高品質を維持し、理想的には1024×1024ピクセルのサイズに統一します。これより小さいサイズでも訓練は可能ですが、あまりに小さすぎたりぼやけた写真は避けるべきです。解像度が低い写真を使用すると、生成される画像の品質も低下してしまいます。 多角度撮影の重要性...